

TL;DR; Work Contracts is an alternative to MPMC queues for use in processing asynchronous tasks. It offers superior performance when compared to leading lock-free MPMC queue implementations - especially under high contention.
In the beginning:
Many years ago I came up with a technique for managing asynchronous tasks which, to the best of my knowledge was, and still is, very different from existing approaches. The typical approach involves pushing tasks into a queue and executing the tasks once they reach the front of the queue. In general it is desirable to have many threads consume the tasks from the queue concurrently thereby allowing multiple tasks to be executed either concurrently or in parallel on different CPUs. For the sake of efficiency, the queue typically takes the form of a multi-producer/multi-consumer queue (MPMC Queue) and is usually a "lock free" design which improves throughput by reducing the overhead required to synchronize access to the queue during push/pop operations. Creating an efficient lock free MPMC queue is a non trivial task and can be prone to subtle race conditions if not implemented with exacting attention to details. Fortunately, there are many implementations of lock free MPMC queues which are widely available. Some are more efficient than others, and, each has their own caveats and trade offs such as reduced throughput under heavy contention, weak ordering (tasks can be consumed in a different order than that under which they were produced), fixed capacity queues, dynamic capacity queues, etc.
Obviously, it is desirable to reduce the overhead of producing and consuming from a MPMC queue as much as is possible since each task consumed will have its overall latency penalized by the amount of time it takes to synchronize the removal of the task from the queue. In low latency environments it is critical to reduce this penalty much as is possible. However, by their very nature, all MPMC queues require synchronization and so there is always some latency penalty to be paid. And, as it turns out, synchronizing access to a task queue is almost never the end of the synchronization woes. But more on this later.
What we are (usually) trying to solve?
Over the decades I have concluded that the following conditions are generally true where asynchronous tasks are concerned:
For example, consider a common situation where software polls an interface for incoming packets and then tasks sockets to receive those packets. Since our interest here is accomplish this behavior asynchronously we will have to perform these socket receives with threads other than the polling thread.
With a task queue based architecture it becomes necessary to create and queue a task which will eventually call receive for the socket. Presumably this task, being part of a general task queue system, will be abstracted in some fashion such that it can be customized for our specific task; i.e. to schedule receive for the socket. This might be done by overriding virtual functions on some base task class, or by use of std::function or some similar approach, or by any number of another approaches entirely. Furthermore, the specifics of which socket to receive must somehow be encapsulated within that task for use in the future at the time when receive is actually scheduled. Further complications include how that task is allocated. Is it from a pool? Is it directly copy constructed into a slot within a fixed length circular queue? How big is this allocation? Is it sufficiently sized to accommodate any sized task? Are all tasks the same size regardless of their nature? Let's pause to picture what such a system might look like:
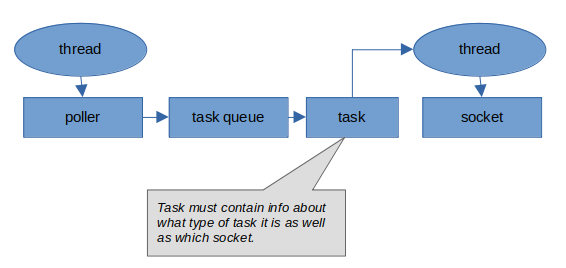
Additionally, suppose a second task were in the queue to operate on the same socket. How does this system prevent a second thread from processing this second task while the initial receive task might still be underway?
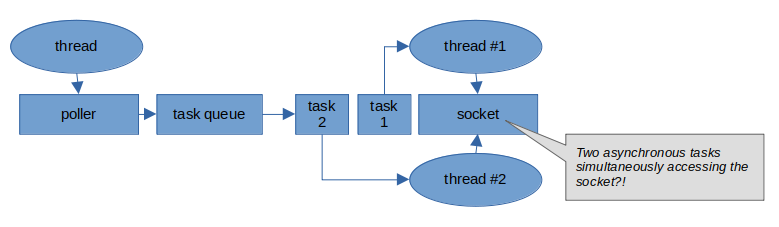
So many complications for a situation where the task (call receive on the socket) is deterministically the next logical task once the socket has been polled. If only there were a way to get the benefits of callbacks in such situations. After all, when a socket has been selected by the polling thread, we know that the next task is to schedule receive and we know which socket is involved.
Work contracts: Pros, cons and caveats:
Caveats:
Queues? We don't need no stinking queues!
In contrast to the classic "Task Queue" approach the "Work Contract" approach eschews queues entirely. Instead, "Tasks" (referred to as "work contracts") are stored as leafs of binary heaps which support lock free manipulation. Work contracts are sufficiently different from tasks while accomplishing the same basic goals. As such, it is beneficial to establish some basic terminology prior to continuing.
work contract: an object defining a specific work function (a task) as well as an optional release function (a kind of task destructor)
work contract group: a container for a group of work contracts (effectively the lock free binary heap)
work function: a repeatable function that will be executed asynchronously after the work contract has been scheduled
release function: an optional function which will be executed asynchronously once after the work contract has been released
scheduled: when a work contract is scheduled is it flagged as ready for asynchronous execution of its work function (the equivalent of enqueue for task queues)
executed: the act of executing the work function via a worker thread asynchronously (the equivalent of dequeue for task queues)
released: the final state of a work contract prior to its destruction. When a work contract is released it is flagged for destruction and
scheduled one final time. However, because it is flagged for destruction when it is asynchronously executed for the final time, the release function
shall be executed rather than the work function. It is fair to think of the release function as akin to a destructor for the work contract.
Clever use of the release function can be used to create safer and more efficient code. See the source code for examples.
The basic life cycle of a work contract is:
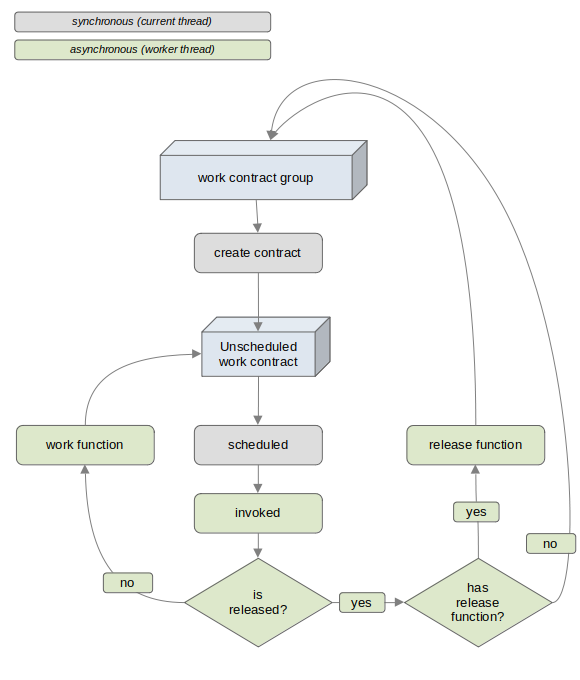
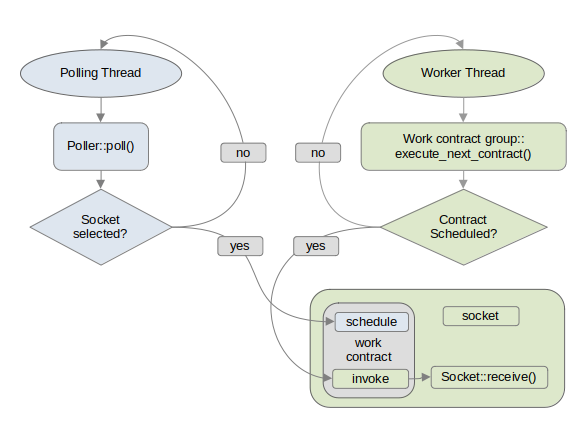
In the above illustration a work contract is created and its work function is assigned to execute receive on the associated socket. When the polling thread selects the given socket it schedules the work contract associated with that socket which flags the work contract as ready for asynchronous processing. When the worker thread identifies a scheduled work contract it executes the work contract's work function, which is to call receive on that socket. Here we stop to note the following:
Benchmarks: "Show me the numb-ahs!"
Ignoring my Boston accent ... for the sake of those who want to see performance numbers before investing time into reading code examples, we now skip right to the fun part - the benchmarking. It is difficult to draw a direct comparison of work contracts to any given MPMC queue because work contracts is intended to solve a particular usage case where MPMC queues are typically used. But any given MPMC queue implementation likely isn't specifically intended for use exclusively as an asynchronous task queue. With this in mind I have chosen to compare work contracts against two of the most efficient MPMC queues. Specifically, the ConcurrentQueue from MoodyCamel and TBB concurrent_queue. MoodyCamel's ConcurrentQueue has several modes of operation. It is beyond the scope of this benchmark to do any fine tuning to identify the best mode of operation here. Consequently, this benchmark uses the default mode for ConcurrentQueue as it is "out of the box".
The test machines:
Tests where taken on two different machines. In each case only the machine's physical cores are utilized (no hyperthreading) and
each worker thread has its affinity set to a different physical core.
The benchmark Tests:
Low Contention: Task is to calculate number of primes up to 1000 using sieve of Eratosthenes
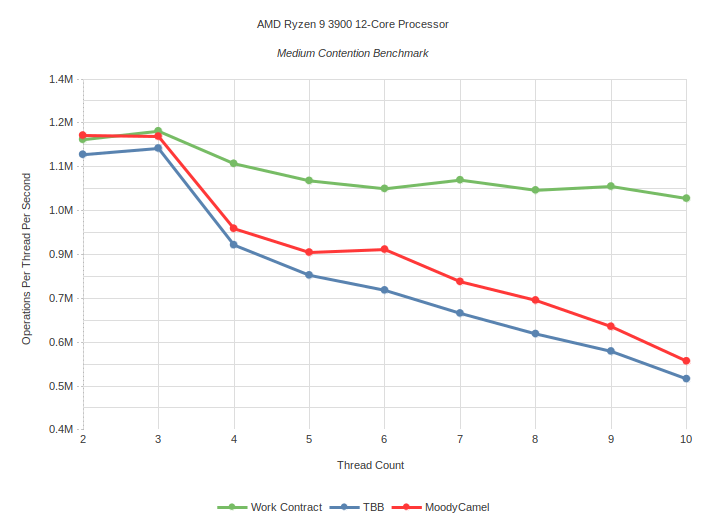
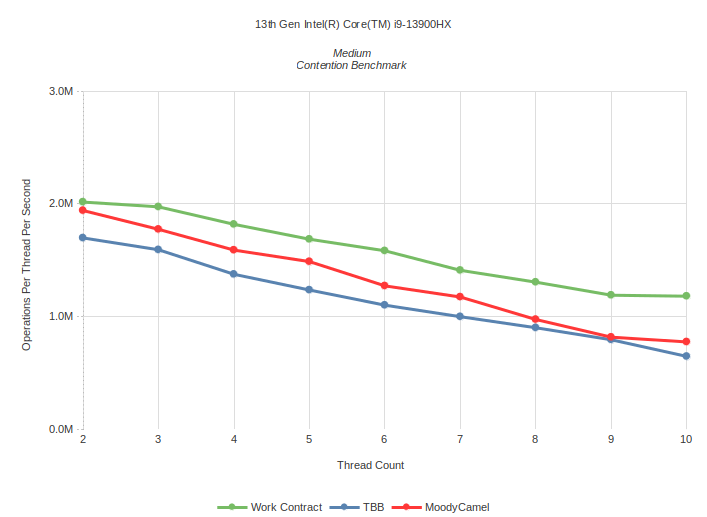
Medium Contention: Task is to calculate number of primes up to 300 using sieve of Eratosthenes
High Contention: Task is to calculate number of primes up to 100 using sieve of Eratosthenes
Maximum Contention: Task is empty function which does nothing
The process:
Create a simple task which consumes a modest amount of CPU when executed and repeatedly execute that task
asynchronously for some duration of time (10 seconds in this case). This task is specifically crafted as
to avoid contention for resources across threads.
The test for both Moody Camel and TBB is as follows:
Finally, after the 10 seconds elapses the worker threads are shutdown and several metrics are gathered. These include, the overall number tasks executed, the average number of tasks per thread per second, standard deviation of each individual task's execution count, and standard deviation of how many tasks each thread executed.
Low Contention: Task is to calculate number of primes up to 1000 using sieve of Eratosthenes
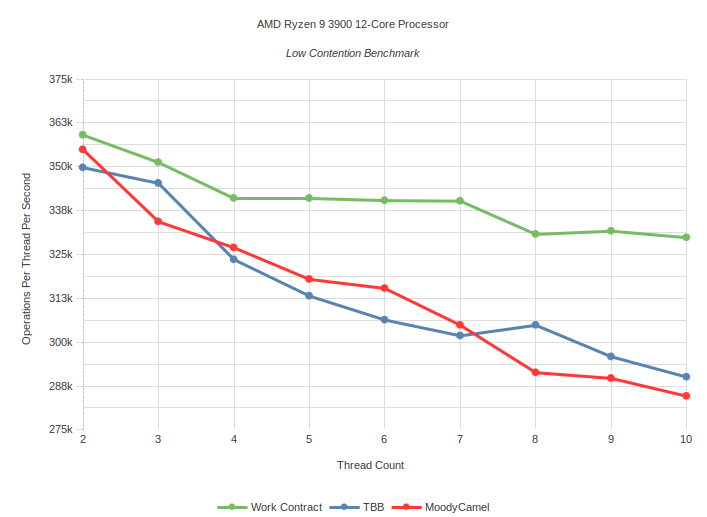
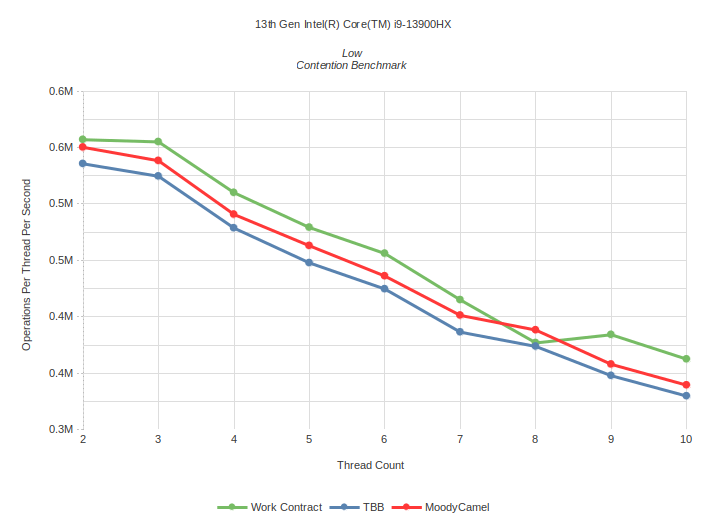
Medium Contention: Task is to calculate number of primes up to 300 using sieve of Eratosthenes
High Contention: Task is to calculate number of primes up to 100 using sieve of Eratosthenes
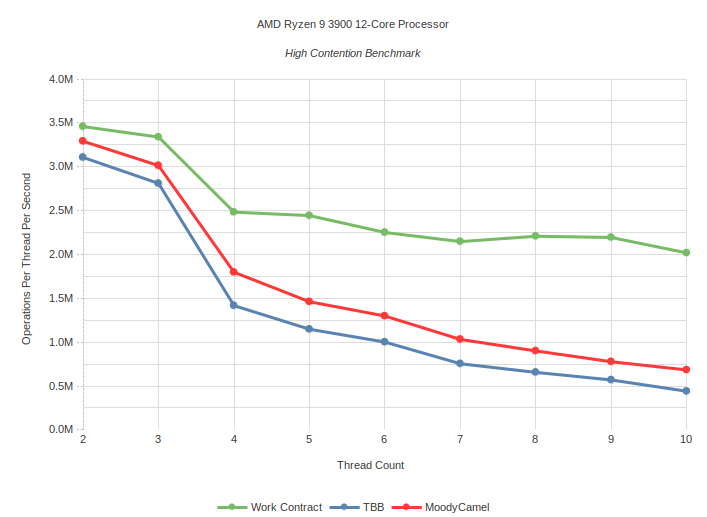
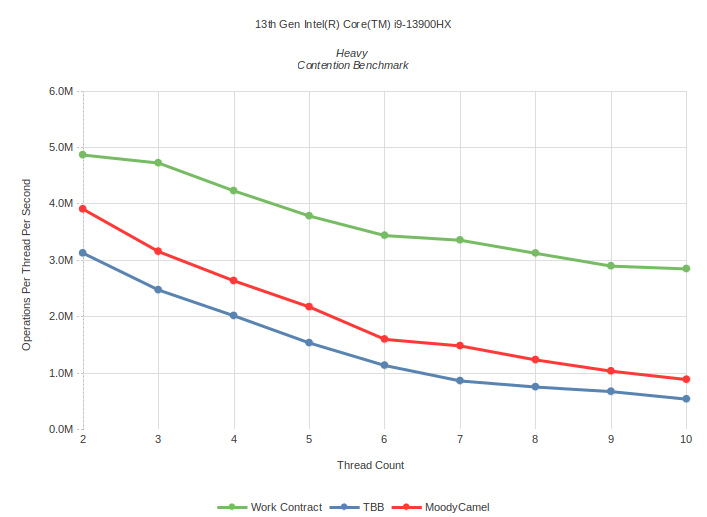
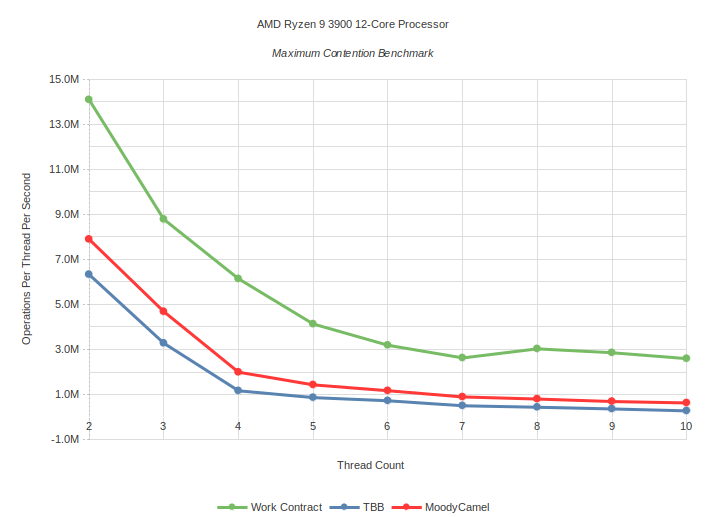
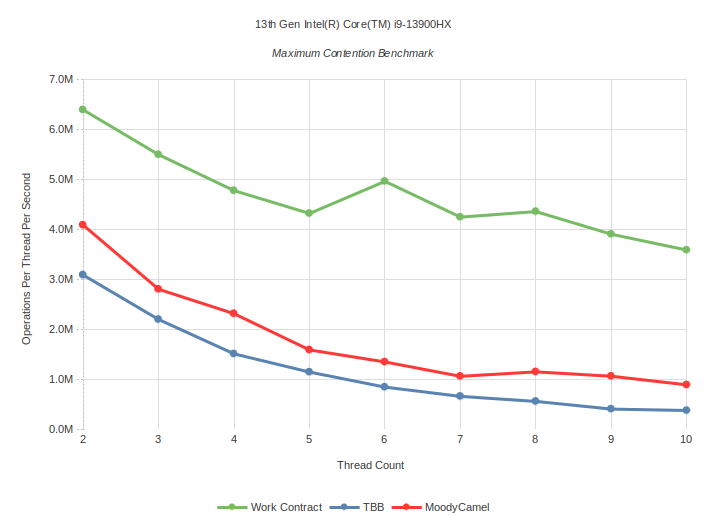
Maximum Contention: Task is empty function which does nothing
Coefficient of Variation for execution of tasks (High contention at 10 threads):
| TBB | Moody Camel | Work Contract | |
| Intel | < 0.001 | 0.759 | 0.001 |
| AMD | < 0.001 | 0.706 | 0.001 |
Coefficient of Variation for work executed by each thread (High contention at 10 threads):
| TBB | Moody Camel | Work Contract | |
| Intel | 0.882 | 0.081 | 0.104 |
| AMD | 0.153 | 0.052 | 0.096 |
Usage guide:
How to use work contracts as well as code examples are found in part two